一种基于不确定性动态权重经验回放的HITL-DRL方法
论文相关信息
本文内容取自[1]。
研究背景及意义
人在环深度强化学习(Human-in-the-Loop Deep Reinforcement Learning, HITL-DRL)逐渐成为AI领域的重要研究方向。该方法通过融合人类的知识与经验,有效缓解了传统深度强化学习存在的采样效率低、安全性不足等缺陷(missing reference),并在自动驾驶、机器人控制[2]及大语言模型训练[3]等场景中展现出应用潜力。然而,HITL-DRL对人工监督的高度依赖不仅显著增加了训练成本,还限制了其在复杂环境中的大规模应用。
针对降低人类指导成本的需求,现有研究主要聚焦于两类技术路径:其一为模仿学习[4],该方法在简单任务中表现优异,但难以应对高维复杂环境中的策略退化问题;其二为约束驱动机制[5],通过设计奖励函数优化人类数据的利用效率,却受限于稀疏奖励函数的设计难题。因此,我们试图通过算法在保证算法学习效率的同时,深度挖掘人类指导数据的潜在价值以降低对人类的指导需求。
本文工作
衡量机器决策不确定性水平
本节利用概率建模评估决策不确定性,作为动态权重机制的基础。以深度强化学习中的策略网络为例,传统方法将网络参数视为固定值,而我们将参数看作存在多种可能性的随机变量(类似天气预报中的概率预测)。通过引入贝叶斯更新机制,系统能像拼图一样持续整合历史交互数据,动态调整参数的可能性分布。具体采用蒙特卡洛随机采样技术,生成大量候选动作样本,通过分析这些动作的集中趋势和分散程度(比如80%样本选择刹车、20%选择转向),直观量化当前决策的可信度。这种量化结果将帮助智能体在复杂环境中识别高风险决策,优先选择更可靠的行动方案。
具体的计算方法如下:
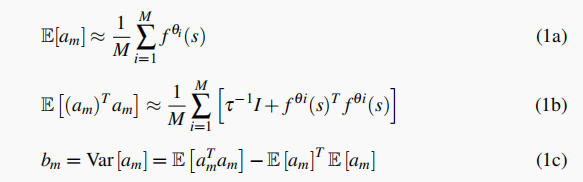
图1 机器不确定性水平衡量
加权函数设计
本研究通过设计动态权重函数,有效区分自主探索与专家经验在学习过程中的优先级,从而提高数据利用效率和学习稳定性。具体而言,权重分配遵循以下三项原则:(1)降低高风险自主决策样本的学习权重,避免强化低效或错误的策略;(2)优先学习专家示范,以加速策略优化并提高决策的可靠性;(3)确保整体权重归一化,保证不同数据源之间的平衡,以维持训练的稳定性和收敛性。此外,本文进一步对该动态加权策略的理论基础进行了推导,并提供了相应的分析,详细内容可参考 [1]。
实验结果
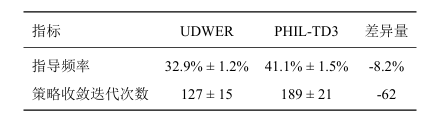
为验证上述方法的有效性,本文进行了对比实验,实验结果如表 1 所示。在实验过程中,我们采用UDWER 方法以降低人类指导成本,并在任务时长约束为 35 分钟的条件下,对比其与基线方法在人类干预触发频率上的差异。实验结果表明,UDWER 方法的人类干预触发频率较基线方法降低了 8.2 个百分点,表明该方法能够有效减少对人工监督的依赖,提高训练过程的自主性。此外,UDWER 通过不确定性感知机制减少了不必要的人工介入,同时利用动态加权经验回放优化了数据利用效率,从而在保证学习效果的同时显著降低了人类专家的负担。因此,实验结果充分验证了本文提出方法在提升采样效率和降低人工干预需求方面的优越性。
为验证UDWER的有效性,设计了 训练回报对比实验 和 任务完成情况对比实验,并将实验结果分别呈现在 图 2 和 图 3 中。实验过程中,我们对比了 UDWER 与现有基线方法在不同训练阶段的回报变化趋势、收敛速度以及最终任务完成率。结果表明,UDWER 在训练过程中收敛速度更快,回报更稳定,并在最终任务完成率上优于基线方法,说明其能够有效提升学习效率并降低训练不稳定性。
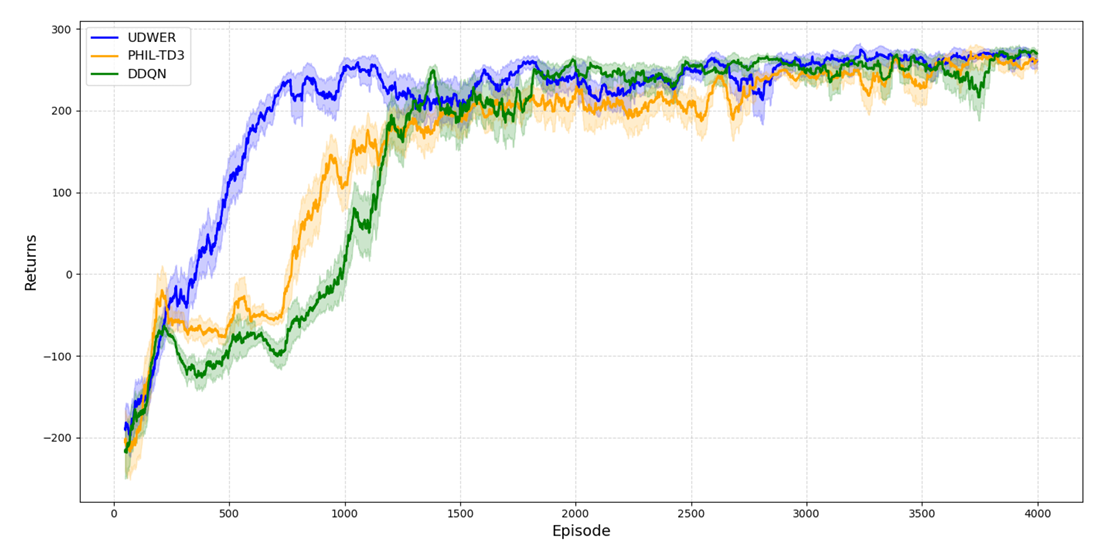
图2 训练回报对比
UDWER方法在任务成功率方面具有显著优势。该方法在训练初期即展现出快速收敛特性,仅经历约400轮次训练后,成功率便稳定维持在较高水平(如90%以上),体现出对任务环境的高效适应能力与长期训练稳定性。相较之下,基线算法呈现出较大波动性,其成功率曲线存在明显震荡(如60%-80%区间波动),收敛速度相对滞后,且最终稳定值较UDWER低约15%-20%,这直观反映了传统方法在策略鲁棒性和环境适应性方面的局限性。
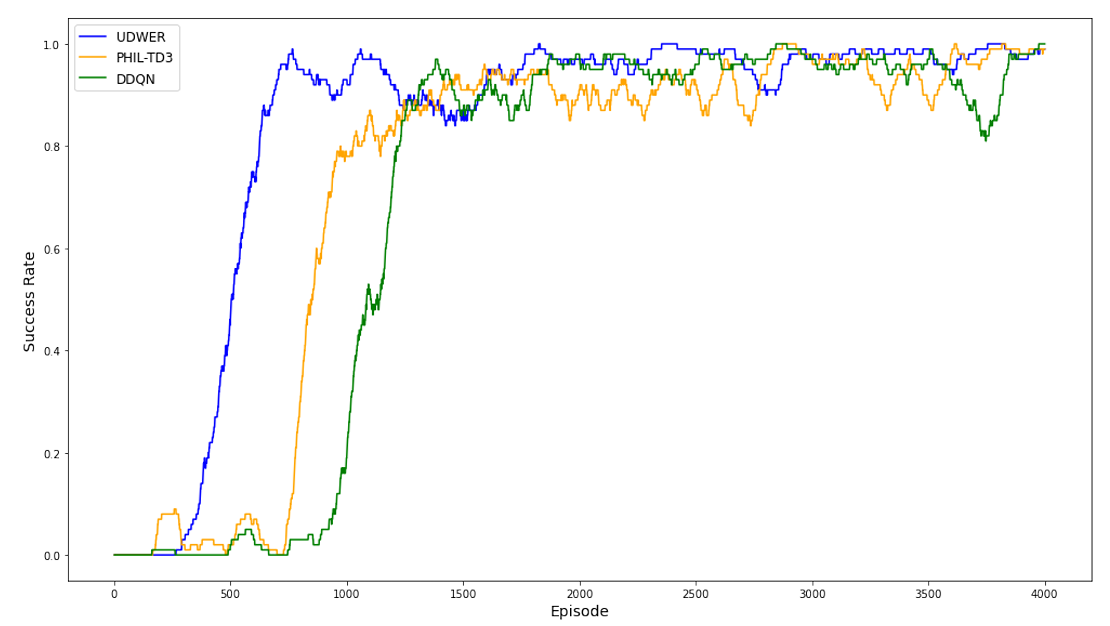
图3 任务完成情况对比
参考文献
- [1]“Uncertainty-Based Dynamic Weighted Experience Replay for Human-in-the-Loop Deep Reinforcement Learning,” in In The 2nd International Conference on Artificial Intelligence and Human-Computer Interaction 2024, 2024.
- [2]J. Wu, Y. Zhou, H. Yang, Z. Huang, and C. Lv, “Human-guided reinforcement learning with sim-to-real transfer for autonomous navigation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 12, pp. 14745–14759, 2023.
- [3]L. Ouyang et al., “Training language models to follow instructions with human feedback,” Advances in neural information processing systems, vol. 35, pp. 27730–27744, 2022.
- [4]B. Hilleli and R. El-Yaniv, “Toward Deep Reinforcement Learning Without a Simulator: An Autonomous Steering Example,” Proceedings of the AAAI Conference on Artificial Intelligence, Jun. 2022.
- [5]M. Vecerík et al., “Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards,” arXiv: Artificial Intelligence,arXiv: Artificial Intelligence, Jul. 2017.